A point x∗ satisfying the constraints h1(x∗)=0,…,hm(x∗)=0 is said to be a regular point of the constraints if the gradient vectors ∇h1(x∗),…,∇hm(x∗) are linearly independent.
Let Dh(x∗) be the Jacobian matrix of h=[h1,…,hm]⊤ at x∗, given by
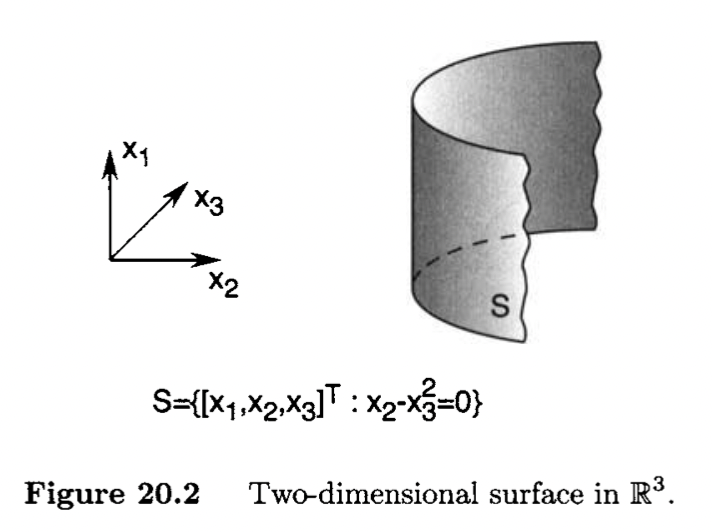
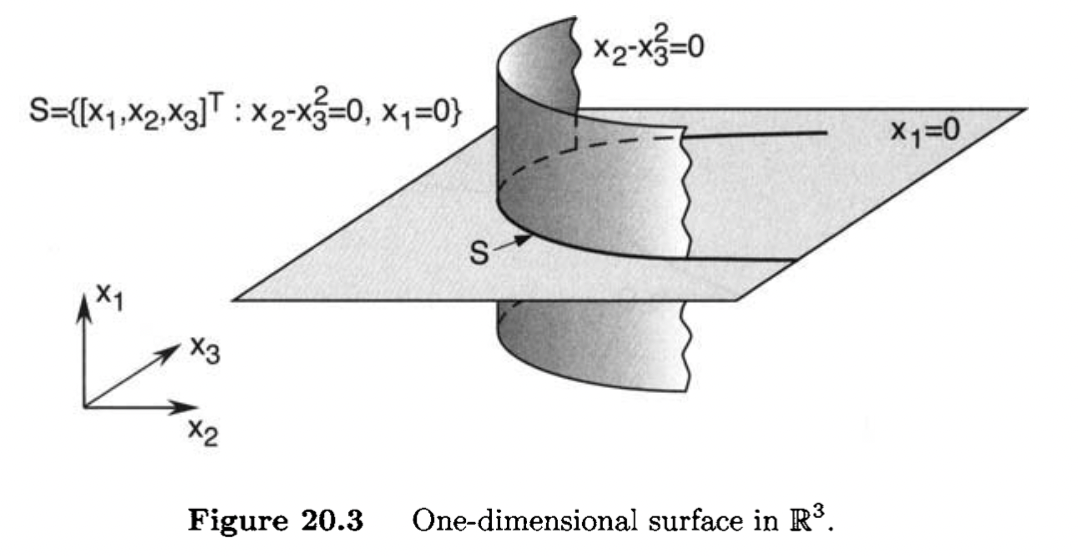
A curve C on a surface S is a set of points {x(t)∈S:t∈(a,b)}, continuously parameterized by t∈(a,b); that is, x:(a,b)→S is a continuous function.
A graphical illustration of the definition of a curve is given in Figure 20.4. The definition of a curve implies that all the points on the curve satisfy the equation describing the surface. The curve C passes through a point x∗ if there exists t∗∈(a,b) such that x(t∗)=x∗.
Intuitively, we can think of a curve C={x(t):t∈(a,b)} as the path traversed by a point x traveling on the surface S. The position of the point at time t is given by x(t).
Figure 20.5 Geometric interpretation of the differentiability of a curve.
The curve C={x(t):t∈(a,b)} is twice differentiable if
x¨(t)=dt2d2x(t)=⎣⎡x¨1(t)⋮x¨n(t)⎦⎤
exists for all t∈(a,b).
Note that both x˙(t) and x¨(t) are n-dimensional vectors. We can think of x˙(t) and x¨(t) as the velocity and acceleration, respectively, of a point traversing the curve C with position x(t) at time t. The vector x˙(t) points in the direction of the instantaneous motion of x(t). Therefore, the vector x˙(t∗) is tangent to the curve C at x∗ (see Figure 20.5).
We are now ready to introduce the notions of a tangent space. For this recall the set
The tangent space at a point x∗ on the surface S={x∈Rn:h(x)=0} is the set T(x∗)={y:Dh(x∗)y=0}.
Note that the tangent space T(x∗) is the nullspace of the matrix Dh(x∗) :
T(x∗)=N(Dh(x∗)).
The tangent space is therefore a subspace of Rn.
Assuming that x∗ is regular, the dimension of the tangent space is n−m, where m is the number of equality constraints hi(x∗)=0. Note that the tangent space passes through the origin. However, it is often convenient to picture the tangent space as a plane that passes through the point x∗. For this, we define the tangent plane at x∗ to be the set
TP(x∗)=T(x∗)+x∗={x+x∗:x∈T(x∗)}.
Figure 20.6 Tangent plane to the surface S at the point x∗.
Suppose that x∗∈S is a regular point and T(x∗) is the tangent space at x∗. Then, y∈T(x∗) if and only if there exists a differentiable curve in S passing through x∗ with derivative y at x∗.
Note that the normal space contains the zero vector. Assuming that x∗ is regular, the dimension of the normal space N(x∗) is m. As in the case of the tangent space, it is often convenient to picture the normal space N(x∗) as passing through the point x∗ (rather than through the origin of Rn ). For this, we define the normal plane at x∗ as the set
NP(x∗)=N(x∗)+x∗={x+x∗∈Rn:x∈N(x∗)}.
Figure 20.9 illustrates the normal space and plane in R3 (i.e., n=3 and m=1)
We now show that the tangent space and normal space are orthogonal complements of each other (see Section 3.3).
To better understand the idea underlying this theorem, we first consider functions of two variables and only one equality constraint. Let h:R2→R be the constraint function. Recall that at each point x of the domain, the gradient vector ∇h(x) is orthogonal to the level set that passes through that point. Indeed, let us choose a point x∗=[x1∗,x2∗]⊤ such that h(x∗)=0, and assume that ∇h(x∗)=0. The level set through the point x∗ is the set {x:h(x)=0}. We then parameterize this level set in a neighborhood of x∗ by a curve {x(t)}, that is, a continuously differentiable vector function x:R→R2 such that
We can now show that ∇h(x∗) is orthogonal to x˙(t∗). Indeed, because h is constant on the curve {x(t):t∈(a,b)}, we have that for all t∈(a,b),
h(x(t))=0.
Hence, for all t∈(a,b),
dtdh(x(t))=0
Applying the chain rule, we get
dtdh(x(t))=∇h(x(t))⊤x˙(t)=0.
Therefore, ∇h(x∗) is orthogonal to x˙(t∗).
Now suppose that x∗ is a minimizer of f:R2→R on the set {x:h(x)= 0 ). We claim that ∇f(x∗) is orthogonal to x˙(t∗). To see this, it is enough to observe that the composite function of t given by
ϕ(t)=f(x(t))
achieves a minimum at t∗. Consequently, the first-order necessary condition for the unconstrained extremum problem implies that
dtdϕ(t∗)=0.
Applying the chain rule yields
0=dtdϕ(t∗)=∇f(x(t∗))⊤x˙(t∗)=∇f(x∗)⊤x˙(t∗)
Thus, ∇f(x∗) is orthogonal to x˙(t∗). The fact that x˙(t∗) is tangent to the curve {x(t)} at x∗ means that ∇f(x∗) is orthogonal to the curve at x∗ (see Figure 20.10).
Figure 20.10 The gradient ∇f(x∗) is orthogonal to the curve {x(t)} at the point x∗ that is a minimizer of f on the curve.
Recall that ∇h(x∗) is also orthogonal to x˙(t∗). Therefore, the vectors ∇h(x∗) and ∇f(x∗) are parallel; that is, ∇f(x∗) is a scalar multiple of ∇h(x∗). The observations above allow us now to formulate Lagrange's theorem for functions of two variables with one constraint.
Let the point x∗ be a minimizer of f:R2→R subject to the constraint h(x)=0,h:R2→R. Then, ∇f(x∗) and ∇h(x∗) are parallel. That is, if ∇h(x∗)=0, then there exists a scalar λ∗ such that
∇f(x∗)+λ∗∇h(x∗)=0.
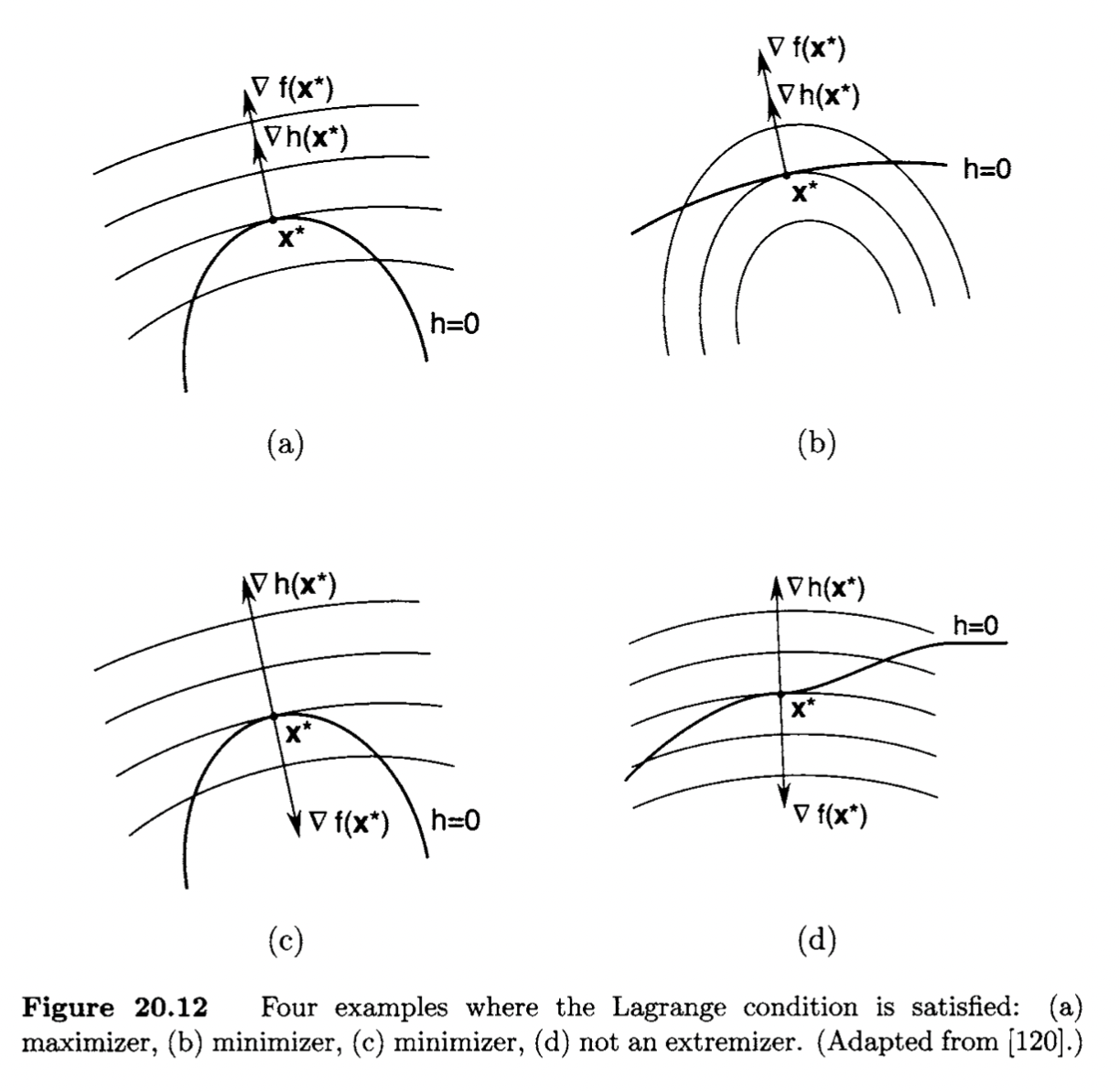
We refer to λ∗ as the Lagrange multiplier. Note that the theorem also holds for maximizers. Figure 20.11 gives an illustration of Lagrange's theorem for the case where x∗ is a maximizer of f over the set {x:h(x)=0}.
Lagrange's theorem provides a first-order necessary condition for a point to be a local minimizer. This condition, which we call the Lagrange condition, consists of two equations:
∇f(x∗)+λ∗∇h(x∗)h(x∗)=0=0.
Note that the Lagrange condition is necessary but not sufficient. In Figure 20.12 we illustrate a variety of points where the Lagrange condition is
Figure 20.11 Lagrange's theorem for n=2,m=1.
satisfied, including a case where the point is not an extremizer (neither a maximizer nor a minimizer).
We now generalize Lagrange's theorem for the case when f:Rn→R and h:Rn→Rm,m≤n
Let x∗ be a local minimizer (or maximizer) of f:Rn→R, subject to h(x)=0,h:Rn→Rm,m≤n. Assume that x∗ is a regular point. Then, there exists λ∗∈Rm such that
for some λ∗∈Rm; that is, ∇f(x∗)∈R(Dh(x∗)⊤)=N(x∗). But by Lemma 20.1,N(x∗)=T(x∗)⊥. Therefore, it remains to show that ∇f(x∗)∈T(x∗)⊥
We proceed as follows. Suppose that
y∈T(x∗).
Then, by Theorem 20.1, there exists a differentiable curve {x(t):t∈(a,b)} such that for all t∈(a,b),
h(x(t))=0,
and there exists t∗∈(a,b) satisfying
x(t∗)=x∗,x˙(t∗)=y.
Now consider the composite function ϕ(t)=f(x(t)). Note that t∗ is a local minimizer of this function. By the first-order necessary condition for unconstrained local minimizers (see Theorem 6.1),
dtdϕ(t∗)=0.
Applying the chain rule yields
dtdϕ(t∗)=Df(x∗)x˙(t∗)=Df(x∗)y=∇f(x∗)⊤y=0.
So all y∈T(x∗) satisfy
∇f(x∗)⊤y=0
Figure 20.13 Example where the Lagrange condition does not hold.
Let x∗ be a local minimizer of f:Rn→R subject to h(x)=0,h:Rn→Rm,m≤n, and f,h∈C2. Suppose that x∗ is regular. Then, there exists λ∗∈Rm such that:
Df(x∗)+λ∗⊤Dh(x∗)=0⊤.
For all y∈T(x∗), we have y⊤L(x∗,λ∗)y≥0.
Proof. The existence of λ∗∈Rm such that Df(x∗)+λ∗⊤Dh(x∗)=0⊤ follows from Lagrange's theorem. It remains to prove the second part of the result. Suppose that y∈T(x∗); that is, y belongs to the tangent space to S={x∈Rn:h(x)=0} at x∗. Because h∈C2, following the argument of Theorem 20.1, there exists a twice-differentiable curve {x(t):t∈(a,b)} on S such that
x(t∗)=x∗,x˙(t∗)=y
for some t∗∈(a,b). Observe that by assumption, t∗ is a local minimizer of the function ϕ(t)=f(x(t)). From the second-order necessary condition for unconstrained minimization (see Theorem 6.2), we obtain
In particular, the above is true for t=t∗; that is,
y⊤[λ∗H(x∗)]y+λ∗⊤Dh(x∗)x¨(t∗)=0.
Adding this equation to the inequality
y⊤F(x∗)y+Df(x∗)x¨(t∗)≥0
yields
y⊤(F(x∗)+[λ∗H(x∗)])y+(Df(x∗)+λ∗⊤Dh(x∗))x¨(t∗)≥0.
But, by Lagrange's theorem, Df(x∗)+λ∗⊤Dh(x∗)=0⊤. Therefore,
y⊤(F(x∗)+[λ∗H(x∗)])y=y⊤L(x∗,λ∗)y≥0,
which proves the result.
Observe that L(x,λ) plays a similar role as the Hessian matrix F(x) of the objective function f did in the unconstrained minimization case. However, we now require that L(x∗,λ∗)≥0 only on T(x∗) rather than on Rn.
The conditions above are necessary, but not sufficient, for a point to be a local minimizer. We now present, without a proof, sufficient conditions for a point to be a strict local minimizer.